Data Wrangling
SDS 192: Introduction to Data Science
For Today
Today we are aiming to understand the data wrangling verbs conceptually. We will practice in three ways:
- Paper-based data wrangling
- Visualizing data wrangling from code
- Writing pseudo-code for data wrangling prompts
Data wrangling is a process for transforming a dataset from its original form into a more relevant form.
Six “verbs” for data wrangling
select()arrange()filter()mutate()summarize()group_by()
Review: What is a data frame?
Key things to remember
- These six verbs are part of the
dplyrpackage in thetidyverse. - When we wrangle data, we start with a data frame and end with a transformed data frame.
- We can string together multiple data wrangling verbs with a pipe (
|>).
Paper-based Data Wrangling
select()
select()enables us to select variables (columns) of interest.
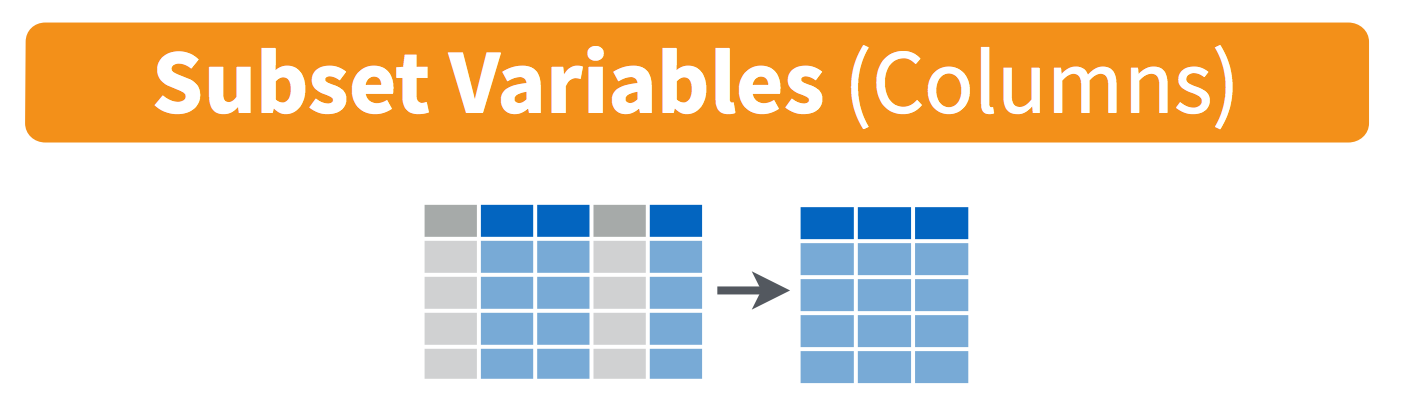
What were Talyor Swift’s album names and the years they were released?
arrange()
arrange()sorts rows according to values in a column- Defaults to sorting from smallest to largest (numeric) or first character to last character (character).
What were Taylor Swift’s three most recent albums?
filter()
filter()subsets observations (rows) according to a certain criteria that we provide.
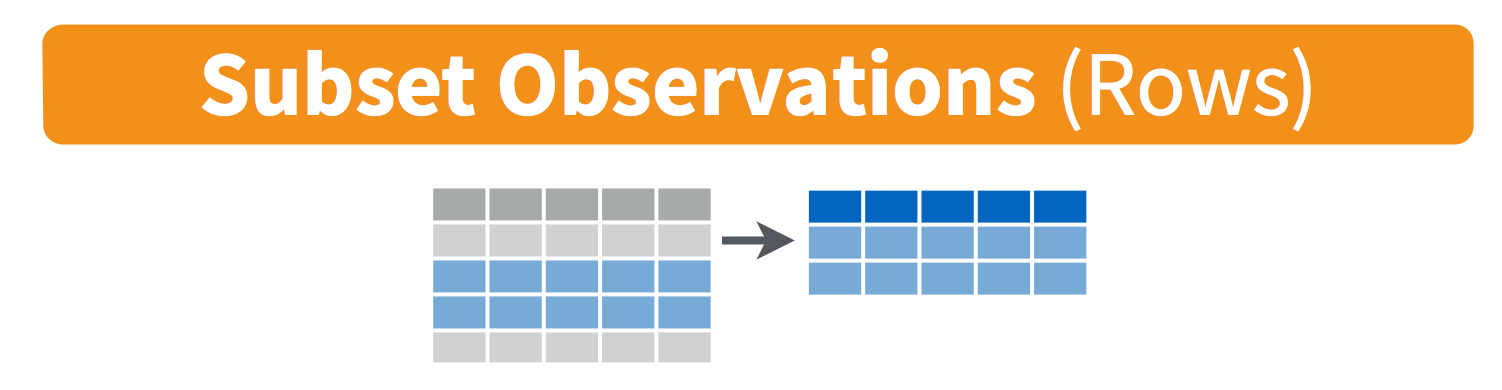
For which albums with the Republic label did Taylor Swift have more than 2,500,000 in US sales?
mutate()
mutate()creates a new variable (column) in a data frame and fills values according to criteria we provide

How many years has it been since the release of each of Taylor Swift’s albums?
Summary functions

What is the most in US sales that a Taylor Swift album has made?
summarize()
summarize()computes a value across a vector of values and stores it in a new data frame
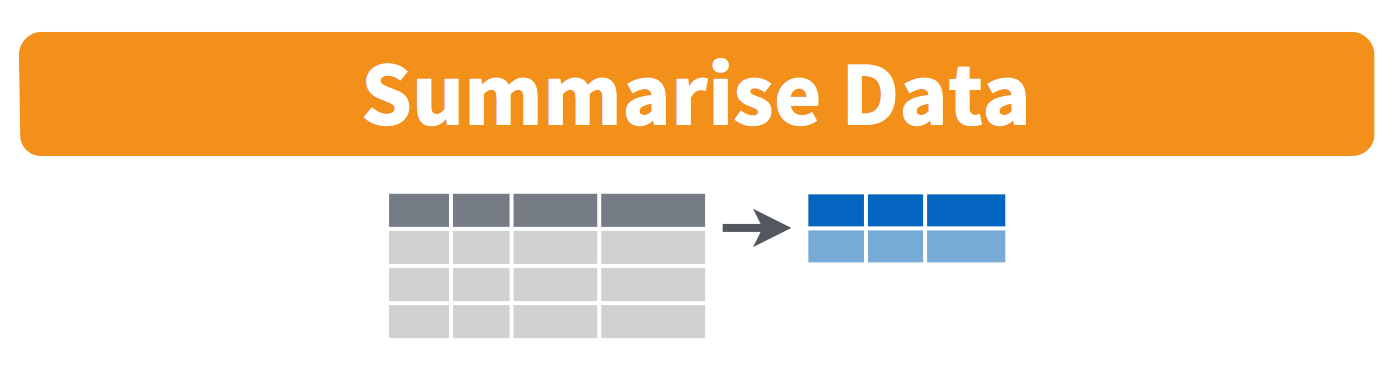
What is the most in US sales that a Taylor Swift album has made?
group_by()
group_by()groups observations with a shared value in a variable- Grouping only changes the metadata of a data frame; we combine
group_by()with other functions to transform the data frame - Values remain in groups unless we
ungroup()it. This is important if we intend to run further operations on the resulting data.
group_by() |> summarize()
group_by()groups observations with a shared value in a variable- When we combine
group_by()andsummarize()we can perform operations within groups
What is the total and max in album sales for each label Taylor Swift has recorded with?
group_by() |> filter()
group_by()groups observations with a shared value in a variable- When we combine
group_by()andfilter()we can filter within groups
Which album had the highest sales for each label Taylor Swift has recorded with?
group_by() |> mutate()
group_by()groups observations with a shared value in a variable- When we combine
group_by()andmutate()we can perform operations within groups and add the resulting variable to the data frame
What percentage of each label’s Taylor Swift sales does each Taylor Swift album represent?
Visualizing Data Wrangling from Code
What were the lending IDs, actions taken, and loan finance details for each loan application?
What were the lending IDs, actions taken, and loan finance details for each loan application?
hmda_ms_2024 |>
select(lei, action_taken, loan_amount:loan_to_value_ratio) |>
head() #Remember that head() shows the first six rows of data!# A tibble: 6 × 5
lei action_taken loan_amount interest_rate loan_to_value_ratio
<chr> <chr> <dbl> <dbl> <dbl>
1 549300G4JDIJPBEO8J… Loan origin… 265000 7.5 80
2 549300CG5TM73650DH… Loan origin… 205000 9 80
3 2549008TT6UNYR7AXF… Loan origin… 145000 6.99 95
4 2549008TT6UNYR7AXF… Application… 485000 NA 90
5 2549008TT6UNYR7AXF… Loan origin… 215000 6.49 68.3
6 549300X08QKYUH256I… Application… 665000 NA NA What were the top six loan amounts requested?
What were the top six loan amounts requested?
# A tibble: 6 × 2
lei loan_amount
<chr> <dbl>
1 5493008OE5JXNTGWD962 935000
2 01J4SO3XTWZF4PP38209 935000
3 549300AENO88GEUWCZ39 885000
4 549300BR7OTD25RTS027 765000
5 549300BR7OTD25RTS027 765000
6 549300FNXYY540N23N64 765000What were the lending IDs, actions taken, loan amounts, and applicant races for each denied loan?
What were the lending IDs, actions taken, loan amounts, and applicant races for each denied loan?
hmda_ms_2024 |>
filter(action_taken == "Application denied") |>
select(lei, action_taken, loan_amount, derived_race) |>
head()# A tibble: 6 × 4
lei action_taken loan_amount derived_race
<chr> <chr> <dbl> <chr>
1 2549008TT6UNYR7AXF54 Application denied 485000 White
2 549300Z9PK8PPMKST414 Application denied 165000 Black or African American
3 549300Z9PK8PPMKST414 Application denied 125000 Native Hawaiian or Other …
4 549300Z9PK8PPMKST414 Application denied 125000 Black or African American
5 54930039UO39UJGI7078 Application denied 555000 White
6 254900R21YNPTNWW1L44 Application denied 45000 Black or African American Which loan applications were denied when the loan to value ratio was less than 50% and the debt-to-income ratio was less than 30%? What were the applicant races and denial reasons?
Which loan applications were denied when the loan to value ratio was less than 50% and the debt-to-income ratio was less than 30%? What were the applicant races and denial reasons?
hmda_ms_2024 |>
filter(action_taken == "Application denied" &
loan_to_value_ratio < 50 &
debt_to_income_ratio %in% c("<20%", "20%-<30%")) |>
select(lei, action_taken, loan_to_value_ratio, debt_to_income_ratio, derived_race, denial_reason) |>
head()# A tibble: 6 × 6
lei action_taken loan_to_value_ratio debt_to_income_ratio derived_race
<chr> <chr> <dbl> <fct> <chr>
1 5493007I0X… Application… 11.2 <20% White
2 549300BR7O… Application… 26 <20% White
3 549300BR7O… Application… 24 <20% Black or Af…
4 549300BR7O… Application… 8 <20% White
5 549300Q3RO… Application… 31.2 20%-<30% White
6 5493000V86… Application… 42.2 20%-<30% White
# ℹ 1 more variable: denial_reason <chr>What would be the monthly interest for each loan?
What would be the monthly interest for each loan?
hmda_ms_2024 |>
mutate(monthly_interest = loan_amount *
((interest_rate / 100 / 12) * (1 + (interest_rate / 100 / 12))^loan_term) /
((1 + (interest_rate / 100 / 12))^loan_term - 1)) |>
select(lei, loan_amount, interest_rate, loan_term, monthly_interest) |>
head()# A tibble: 6 × 5
lei loan_amount interest_rate loan_term monthly_interest
<chr> <dbl> <dbl> <dbl> <dbl>
1 549300G4JDIJPBEO8J84 265000 7.5 360 1853.
2 549300CG5TM73650DH84 205000 9 360 1649.
3 2549008TT6UNYR7AXF54 145000 6.99 360 964.
4 2549008TT6UNYR7AXF54 485000 NA 360 NA
5 2549008TT6UNYR7AXF54 215000 6.49 360 1358.
6 549300X08QKYUH256I80 665000 NA 372 NA What were the average and maximum interest rates?
What were the average and maximum interest rates?
What were the average and maximum interest rates?
What were the average and maximum interest rates?
hmda_ms_2024 |>
summarize(num_applications = n(),
mean_interest = mean(interest_rate, na.rm = TRUE),
median_interest = median(interest_rate, na.rm = TRUE),
max_interest = max(interest_rate, na.rm = TRUE))# A tibble: 1 × 4
num_applications mean_interest median_interest max_interest
<int> <dbl> <dbl> <dbl>
1 34284 7.75 7.12 14.7hmda_ms_2024 |>
group_by(loan_purpose) |>
select(loan_purpose, loan_amount, loan_to_value_ratio) |>
head()# A tibble: 6 × 3
# Groups: loan_purpose [1]
loan_purpose loan_amount loan_to_value_ratio
<chr> <dbl> <dbl>
1 Home Purchase 265000 80
2 Home Purchase 205000 80
3 Home Purchase 145000 95
4 Home Purchase 485000 90
5 Home Purchase 215000 68.3
6 Home Purchase 665000 NA What were the median loan amounts, LRVs, and interest rates for each loan purpose?
What were the median loan amounts, LRVs, and interest rates for each loan purpose?
hmda_ms_2024 |>
group_by(loan_purpose) |>
summarize(num_apps = n(),
median_amnt = median(loan_amount, na.rm = TRUE),
median_lrv = median(loan_to_value_ratio, na.rm = TRUE),
median_int = median(interest_rate, na.rm = TRUE))# A tibble: 2 × 5
loan_purpose num_apps median_amnt median_lrv median_int
<chr> <int> <dbl> <dbl> <dbl>
1 Home Purchase 32139 135000 90 7.12
2 Home improvement 2145 55000 36.2 8 What was the maximum loan amount for each loan purpose?
What was the maximum loan amount for each loan purpose?
hmda_ms_2024 |>
group_by(loan_purpose) |>
filter(loan_amount == max(loan_amount, na.rm = TRUE)) |>
select(lei, loan_amount, loan_to_value_ratio)# A tibble: 3 × 4
# Groups: loan_purpose [2]
loan_purpose lei loan_amount loan_to_value_ratio
<chr> <chr> <dbl> <dbl>
1 Home Purchase 5493008OE5JXNTGWD962 935000 78.9
2 Home Purchase 01J4SO3XTWZF4PP38209 935000 91.3
3 Home improvement NSGZD26XPW2CUM2JKU70 755000 41.7For originated loans, what percentage of the total lent in MS in 2024 does the loan represent for each loan purpose?
For originated loans, what percentage of the total lent in MS in 2024 does the loan represent for each loan purpose?
hmda_ms_2024 |>
filter(action_taken == "Loan originated") |>
group_by(loan_purpose) |>
mutate(total_lent = sum(loan_amount, na.rm = TRUE),
percent_total_lent = loan_amount/total_lent * 100) |>
select(lei, loan_purpose, total_lent, percent_total_lent) |>
head()# A tibble: 6 × 4
# Groups: loan_purpose [1]
lei loan_purpose total_lent percent_total_lent
<chr> <chr> <dbl> <dbl>
1 549300G4JDIJPBEO8J84 Home Purchase 2519570000 0.0105
2 549300CG5TM73650DH84 Home Purchase 2519570000 0.00814
3 2549008TT6UNYR7AXF54 Home Purchase 2519570000 0.00575
4 2549008TT6UNYR7AXF54 Home Purchase 2519570000 0.00853
5 549300X08QKYUH256I80 Home Purchase 2519570000 0.00298
6 549300WO9TX4YEFAC338 Home Purchase 2519570000 0.0125